Fable 5: The First Hit is Free

Artemis II lifts off from Launch Complex 39B, April 1, 2026. Image credit: NASA/Michael DeMocker.
I’ve been extensively testing Fable 5 (Mythos class) after the recent launch. My tests pushed its capabilities from spatial reasoning, critical reasoning, long running research and feedback, multi-step tasks, cinematography / visual design, and other more minor tasks.
Examples:
- help research, design, and procure CNC milled parts
- assist with optics procurement
- do cinematography for my company landing page hero (vigilautonomy.com)
My TLDR feedback is that without a doubt Anthropic cooked with this one. Using Opus 4.8 or its competitor GPT 5.5 xhigh always felt like working with a brilliant intern in their first month - it would do EXACTLY what you said because it was afraid of screwing up and wanted to please you. So if you put a typo in your prompt by gosh it would do its damndest to execute that typo.
On the one hand that’s great? Like I want this AI to be aligned with my intended use, so if I tell it something crazy and I meant it, then I don’t want pushback; just do it. But like most people I make typos all the time, and when I try to use voice to text transcription for technical problems those typos pop up even more often. The ideal alignment here is judgement of my prompt with reasoning to align with the intentions of my words, not the exact words themselves.
Usage Patterns
I do all of my tasks with permissions completely removed - mainly because I think that pattern is the future and the rewards absolutely outweigh the risks. Consider the idea of placing a human (me) in the middle of a loop of operations that may seem inscrutable, so when Fable is asking if I’m okay with an operation like ripgrep or curl or some chained together shell operation my only real reason to interject is not because I disagree with the METHOD, because I do not even attempt to understand the method, it’s because I’m scared of the blast radius and privilege escalation.
I fully believe that as we get more computer use data from Fable 5 users and the flywheel for the frontier labs spins up that post-training will be able to build in better guardrails on the system that make it harder to blow things up. But honestly, the consequences fall on me and I find them worth it to get the full agentic “go off and do this” experience so I can focus on other work.
The only best practice I always engage in is specifying allowed tools in my CLAUDE.md / AGENTS.md that I consider “safe” (chrome browser, ffmpeg, FreeCAD, python virtualenv, isolated worktrees), with explicit instructions to halt immediately if any execution ever requires changing GPU drivers or establishing persistent long running background tasks that will remain after prompt execution. I know the “safety” this brings me is untrue in so many ways, but in my scoped usage it has been effective. I think as long as you don’t say unbounded tasks like “go build me a 1 billion dollar business”, you’re going to be fine. METR is a decent mental heuristic here - as long as the task I’m asking it to do is scopable within 1 day of human work, it’s likely the tool usage is contained enough.1
For example I’ve already seen Fable 5 taking pains to limit its own blast radius even when I give it my personal thinkmaxxing cheat code of “exhaustively”:
- clone my code into an isolated worktree
- spin up an ephemeral and completely separate python virtual environment for the debugging
- use playwright to control an isolated chrome browser
- all of this gets wiped as soon as the task is done
Within the standard bounds of “use my computer to do a thing that is not crazy in a moderately well bounded filesystem with good enough available tools” Fable nails it every time.
Case Study 1: Research, CAD, Procure
I gave Fable the task of producing CAD artifacts of M6 adapter plates for my work at Vigil Autonomy I could send to a machine on demand vendor that would be accepted without any issues, based on hardware casing specifications buried in PDFs and across websites. Consider a few of the steps involved if you were doing this manually:
- for each part go find the relevant spec document. If you’re lucky this is a STEP file, if unlucky it’s a technical drawing buried in a PDF
- Translate that spec to a CAD file of an adapter plate that fits to an M6 optical breadboard
- The CAD artifacts must be acceptance ready for a print on demand vendor (Xometry, SendCutSend) and must use language a human reviewer would understand including acceptable technical drawing PDFs
- Actual uploading of the CAD files to those vendor sites using menu usage to specify taps at each hole for the CNC mill
- Procurement of any mounting equipment from a separate vendor like McMaster-Carr
Put another way this is a complex chain of:
- OCR / Diagram Extraction
- Tool use (CAD)
- Judgement / Reasoning: Do the CAD files we designed make sense? Will they mount to the optical breadboard? Not only does the math check out, but do we have underflush? When we’re operating in field in Kuwait will the heat cause warping?
- Search (for best practices working with vendors)
- Tool Use + Judgement (Browser): now that we have a browser and a vendor site, how do we upload our “correct” CAD files in a way the vendor accepts? How do we examine other vendor sites to identify SKUs that will allow one-shot mounting?

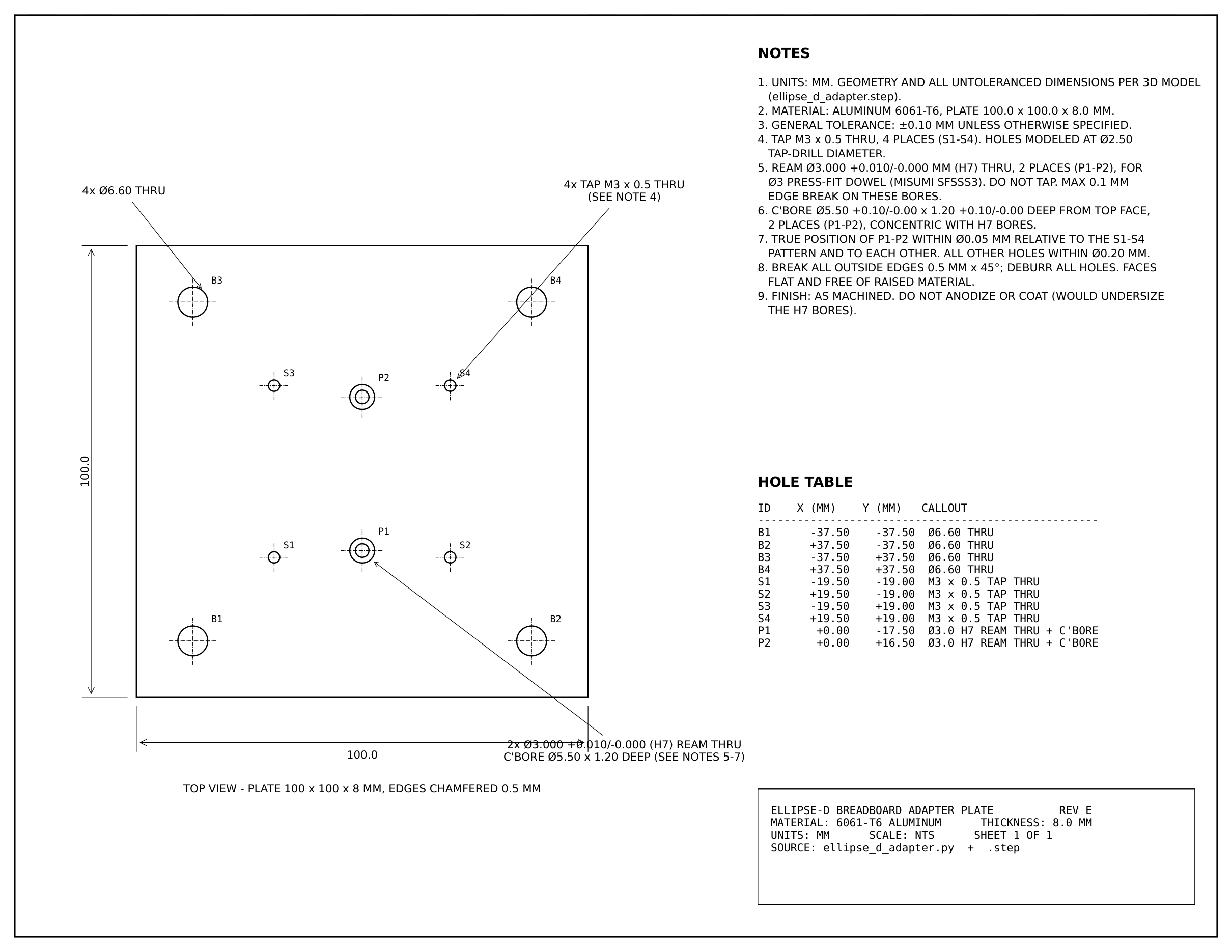
One of the Fable 5 deliverables: the Ellipse-D breadboard adapter plate. CAD render (top) and the vendor-ready technical drawing (bottom) — 6061-T6, M3 taps, H7 dowel bores, callouts a machinist reviewer can act on. Download the drawing PDF.
Analysis
We’ll only know after mounting and field use, but Fable’s planning and execution matched the exact process I would have taken, accomplishing in 3 hours of execution with intermittent feedback to push for continued use in producing more CAD files, and the file synthesis into the browser what would have taken me 3-4 days of work?!
Obviously adapter plates are the ideal solid you could ask a model to generate - they are rigid, bounded, no deformations, single standardized material, and would require a human’s limited mental context to maintain (taps, flush, proud, underflush). But still…. holy shit.
When I asked it to produce validation diagrams showing its understanding of layout on the breadboard, how the screws would work on the board with threading distance, underflush available, it nailed it. When I asked it to confirm that our designs would succeed assuming the tolerances of a 3rd party machinist, Fable explained that obviously it had already considered this, surfaced its thinking tokens to prove it, and made it clear that any error here would be because the machinist did not match their quoted tolerance. Time will tell.
What I love the most is that Fable finally feels like that intern that’s been there for awhile - it’s still slavishly devoted to your goals, but when you’re wrong in your prompts it will reason about your actual goal, do that, and explain that it knew what you meant. I finally had zero times where it executed based on a typo (if I type “produce a STEO cad file” it knows I mean STEP).
I’m guessing as part of their post-training Anthropic is pushing more reasoning tokens during planning before any execution takes place. This makes a ton of sense - for safety aligned AI you need to know the INTENTION of someone’s prompt and filter red team prompts that may read as innocuous but are part of a malicious prompt chain. If someone asks for a list of chemical reagents or electronics related to explosives, reasoning would make a normal person ask “wait, why do you need this? I’m suspicious”, and as future prompts arrive I have that suspicion tied to reasoning, and can apply judgement to stay aligned with my safety policy.
By actively blocking usage for biotech / cybersecurity applications Anthropic is aggressively enforcing their safety mandate2 - which I tend to agree with, and the downstream effect of all the upfront reasoning is a model that nails intention alignment.
The multi-step execution for long running flows is solved. The 1M token contexts are more than enough memory for my isolated workflows, Anthropic has clearly made improvements in context efficiency, and when in doubt memory files are the right solution for picking up from an earlier checkpoint. There was no task I gave it, including the cinematography tasks for vigilautonomy.com, where it failed, we’re talking long running ffmpeg processes, wiring videos into the landing page, and visual analysis of other best practices landing sites.
Case Study 2: Hero Video Production
Until I hire professional designers I’ve been stress testing LLM visual reasoning by repeatedly redesigning the landing page for my company Vigil Autonomy (vigilautonomy.com - hit me up if you like aerial autonomy). LLMs are crushing all of the technical benchmarks but we all know they still don’t nail aesthetic taste.
I think this will continue to be true for a few reasons: (1) design inspiration may be from the distribution (i.e. “inspiration” or “reference”), but new designs are inherently out of distribution (2) design language is ambiguous (what is “clean” design, describe “blue” to a blind person) and (3) LLMs are not inherently human - the designs they produce cannot link to a gut feeling (the Golden Arches suggest nothing in the transistors of an LLM).
I gave it the task of generating a split-screen piece of cinematography I could use in the hero. On the left I had some UAV footage taken during a test flight from above, on the right I wanted paired footage from a ground station detecting the UAV.
You get into interesting problems - on the left it’s more about visually inspiring and cinematic shots with “clean” clip transitions (see even I can’t help use ambiguous language) - on the right I wanted my ground station UAV capture footage, but I didn’t just want hover shots of the drone, I wanted to capture the actual importance of why this data matters - the drone flying from out of frame or a distance towards the camera. I had a loose idea of the clips that looked nice, but didn’t want to do any labeling of frames or help with trajectory segment selection.
Here’s what Fable 5 did:
- first planned how it would accomplish a split-screen design with ffmpeg
- then did clip selection from my ground footage by collating the known UAV trajectories, where the UAV would land in frame in post projection, filtering segments down to make sure even after cropping we’d see the UAV fly into the split screen frame
- executed long running FFmpeg background subprocesses
- updated my landing page to use the video
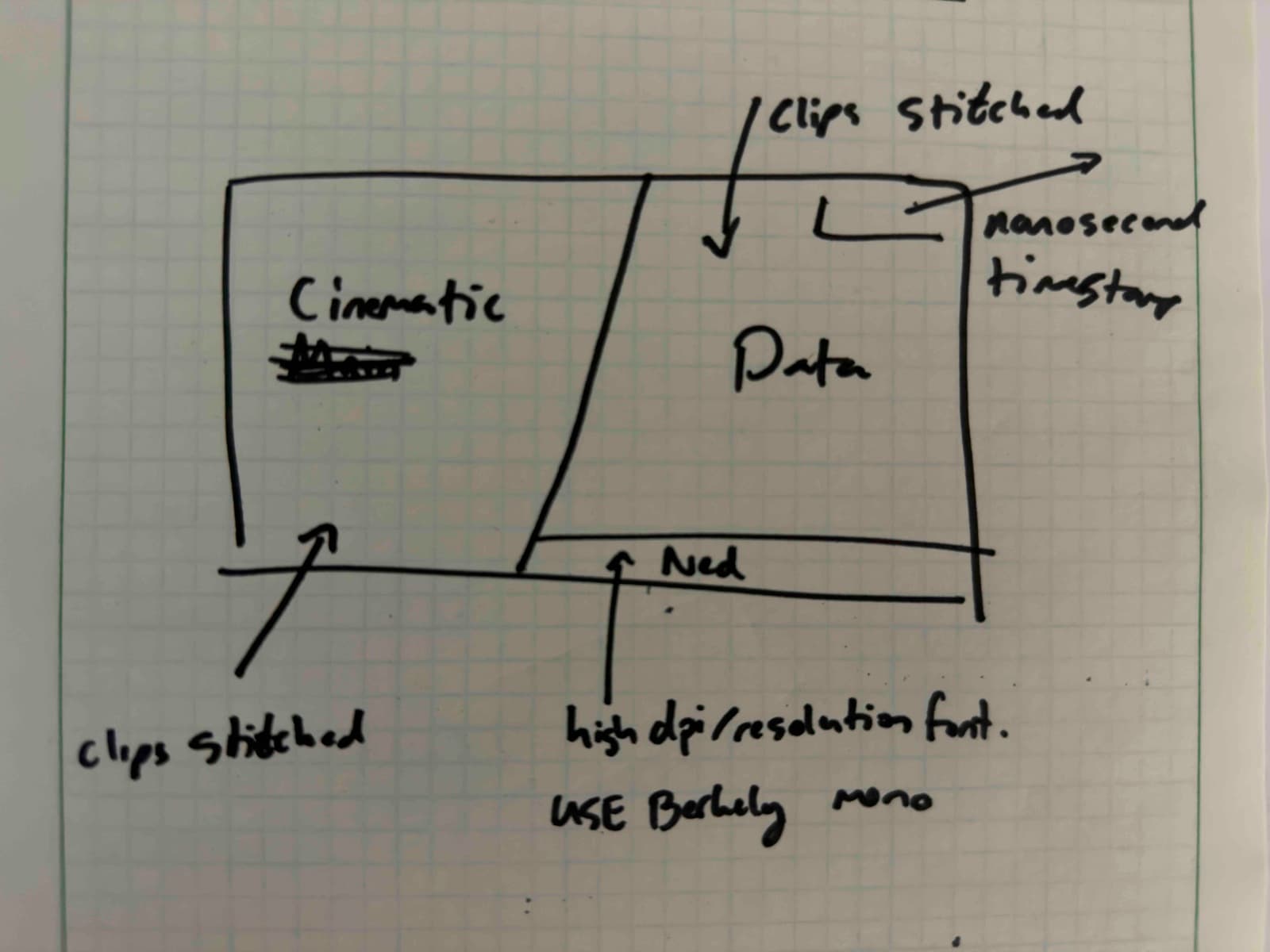
The entire design spec I gave Fable 5: a notebook sketch of the split-screen concept — cinematic on the left, data on the right.

The finished hero billboard on vigilautonomy.com — cinematic UAV footage left, ground-station detection footage right, angled seam per the sketch.
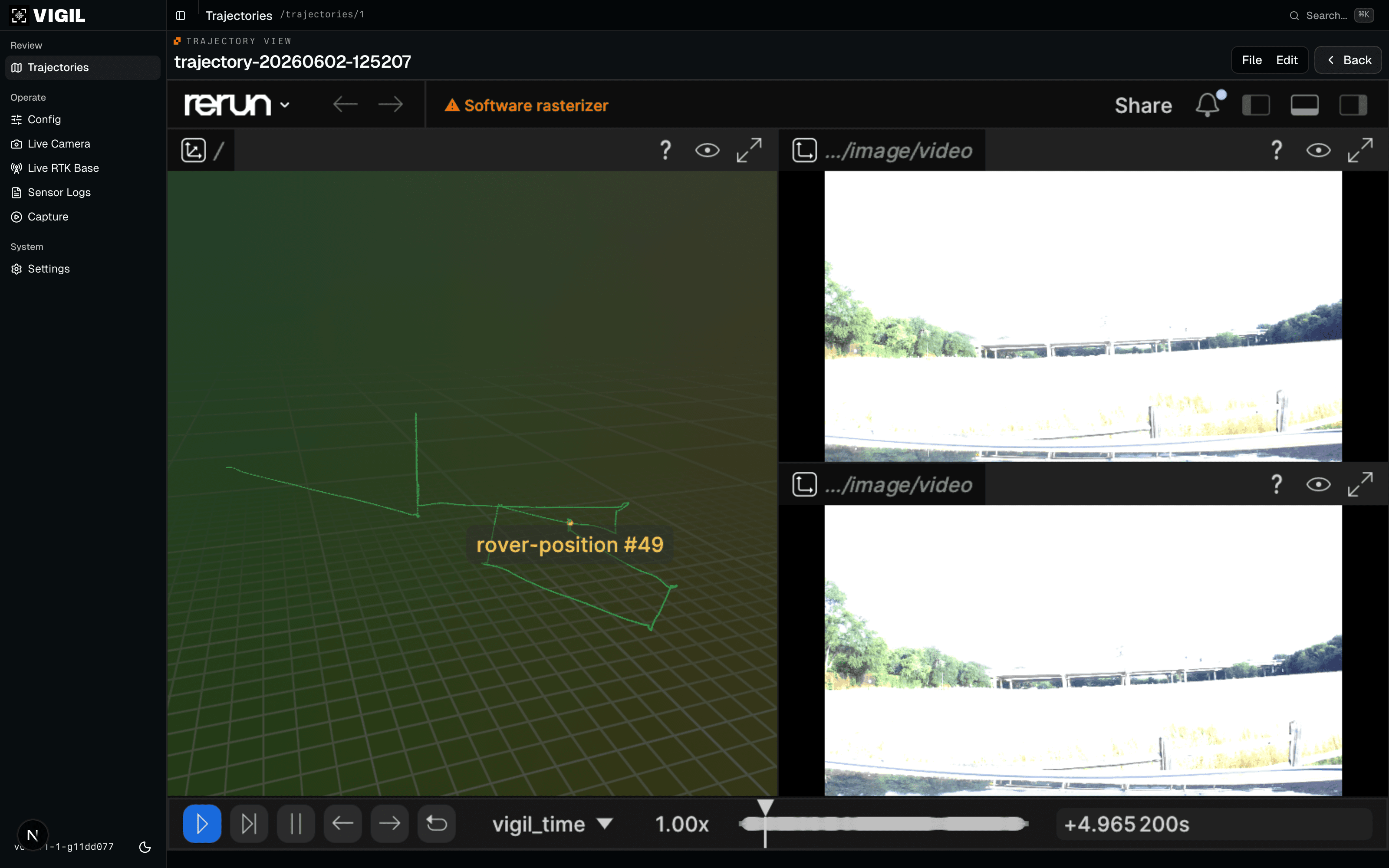
The Vigil UI rerun view for a captured trajectory — the 3D trajectory path with synchronized ground-station camera streams.
Analysis
I don’t know much about cinematography (or if that’s even the right word) but as a computer vision person I’ve spent enough time looking at video to know this looks better than average. Like is it cinema grade? No. Is it better than what I had before? Yes. I liked that Fable 5 was able to handle the FFmpeg usage to do fairly obvious things like clipping / splicing that have always been painful. This was a series of annoying manual steps that are finally in reach because of a tool like this.
Final Thoughts
I’m going to need a better way to work around or with the robots.txt and agents.txt policies more websites are using and that Anthropic respects.3 My intended usage is not malicious - if I want to go buy a list of things from McMaster-Carr, I need to make sure I have the full up-to-date list of SKUs and specs so Fable 5 can reason, but the policies block this (fairly, IMO).
The tradeoff here will be how much I personally care, the future plan is to just have a less scrupulous agent (local LLM) go execute the scrape, build the cache, RAG it, then feed that local file to Fable 5 as it executes. Less token usage and we have the data we need so I can speed run my purchases. I’m dead certain Anthropic / OpenAI / Google / Stripe are fighting to sell this integration for agentic commerce into vendors like this, but in the meantime I still need to accelerate.
Finally, using a model like Fable 5 with high, xhigh, or max effort makes me as the operator wonder if I’m being ambitious enough. It feels like if I can come up with a very long complicated task with a healthy amount of detail the LLM will nail it - so I’m now bounded by big problems I can come up with. This is a joy - drudgery is now outsourced and the hard physical problems that need solving can get my entire focus without sacrificing anything.
Per my earlier article the conclusion is this feels like a step change even if that change is just because the model is 25% better - it has surpassed some threshold. I’m not excited for this to move behind API pricing as it’s currently worth it, but at usage based pricing I’ll have to re-evaluate. I may find it worth it to use it as a coordinator leaving execution to dumber models, but we’re talking about more scaffolding, more mental overhead, more complexity. As they say, the first hit is free.
Footnotes
- METR, “Measuring AI Ability to Complete Long Tasks” (arXiv:2503.14499) — the 50%-task-completion time horizon metric. The heuristic: if a skilled human could finish the task in about a day, the agent’s tool use tends to stay well bounded.
- Anthropic, “Introducing Claude Fable 5 and Claude Mythos 5” — Fable 5 and Mythos 5 share the same underlying model; Fable 5 ships with additional safety measures for dual-use capabilities, while Mythos 5 is available only to approved organizations.
- Anthropic, “Does Anthropic crawl data from the web, and how can site owners block the crawler?” — ClaudeBot, Claude-User, and Claude-SearchBot honor robots.txt directives and anti-circumvention technologies.
Edited with Fable 5